Defaulters Be Gone!
*This project was completed for the Data Science module under IBM’s I-am.vitalize Data Science and AI programme.
About P2P Loans
The rise of Internet usage has driven incredible advances within the finance sector. One of which is the Peer to Peer (P2P) lending platform. Unlike traditional banks, these platforms do not loan out money. Instead, they connect lenders to potential investors. From starting businesses to paying for holidays, lenders could request loans for just about anything. Without the involvement of banks and financial institutions, P2P platforms offer lower interest for lenders and higher returns for investors. All at less restrictive regulations and requirements.
As a result, the P2P market has grown rapidly. However, the lax regulation and requirements come at a cost of higher default rates. In this project, our client, ABZ Capital, is looking to diversify its portfolio by entering this market. Recognising the higher risks compared to the traditional asset classes that they are used to, they wanted a solution that incorporates Data Science to alleviate their concerns.
We operated as a team of 3. I oversaw the Enterprise Design Thinking (EDT) potions of the project and the design and writing of the presentation and mockups.
Kicking Off with Enterprise Design Thinking
We began by framing the challenge with a How Might We statement.
How might we use Data Science to analyse available loans so that our portfolio managers can make better P2P investment decisions quickly?
But to really create a solution that had a positive impact on our end user, we had to put ourselves in their shoes. We developed a persona, Beatrice, and created an empathy map and as-is map of her routine. Through this, we found out that one of her biggest challenges is having to sieve through large numbers of loan requests while worrying if they would default or not.

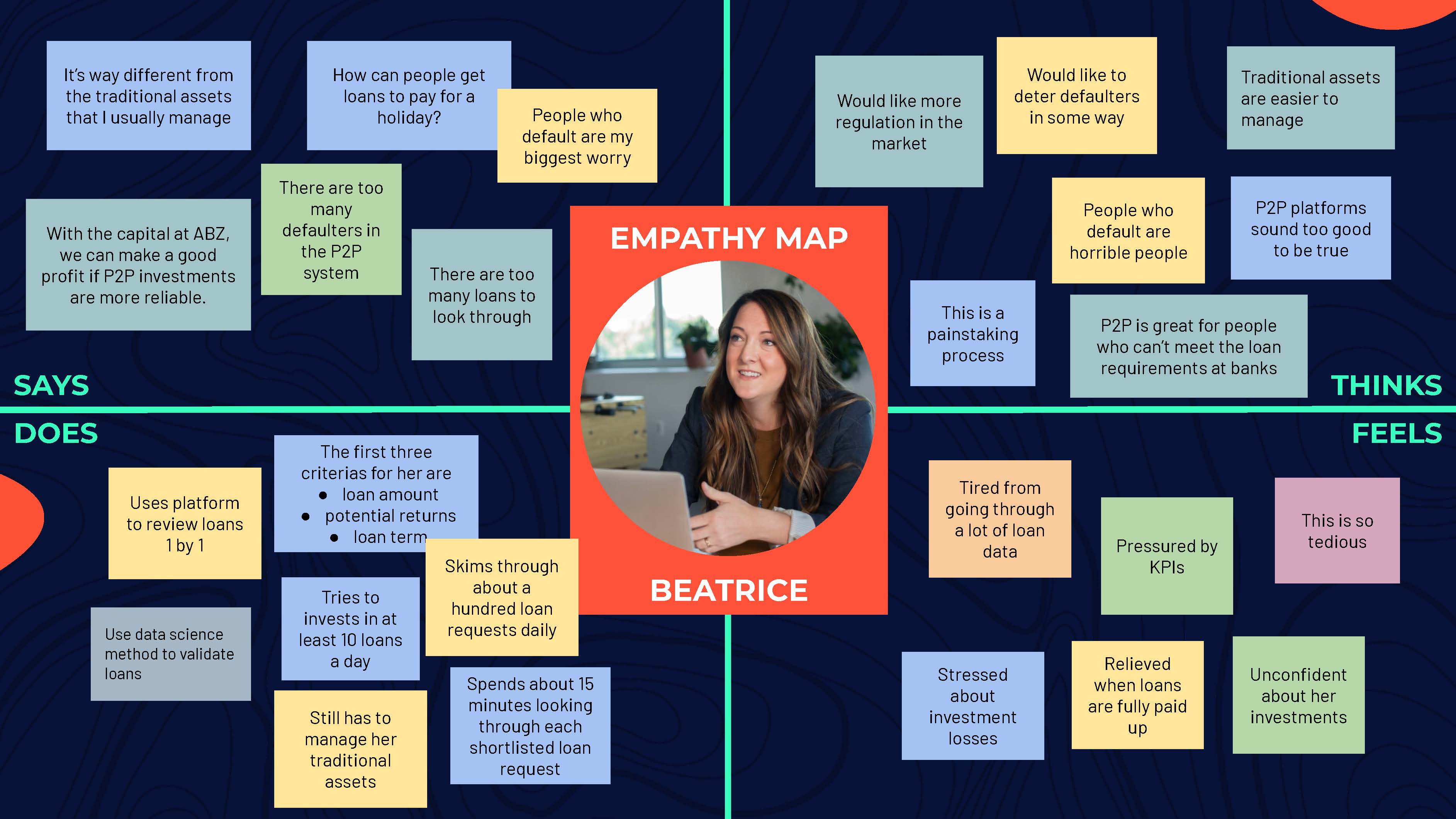
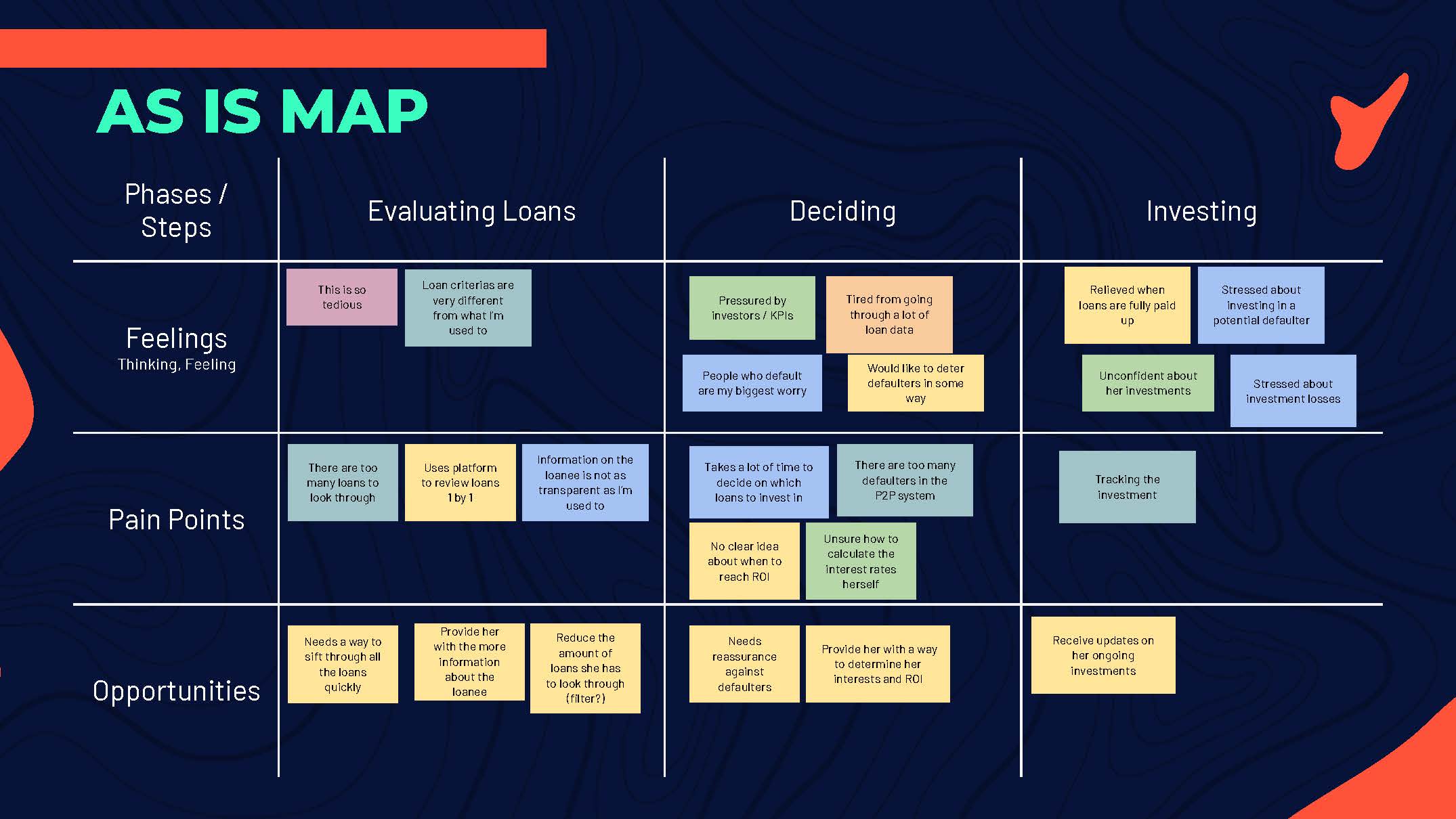
We further condensed this into a needs statement.
Beatrice needs a way to overcome default risks so that she can easily make her P2P investment decisions.
From here, we ideated against the needs statement. We concluded that using data science to predict and flag out possible defaulters from the list of loans was the best solution for Beatrice. This will not only reduce her worry on potential defaulters, but also reduce the amount of loan requests she has to go through.
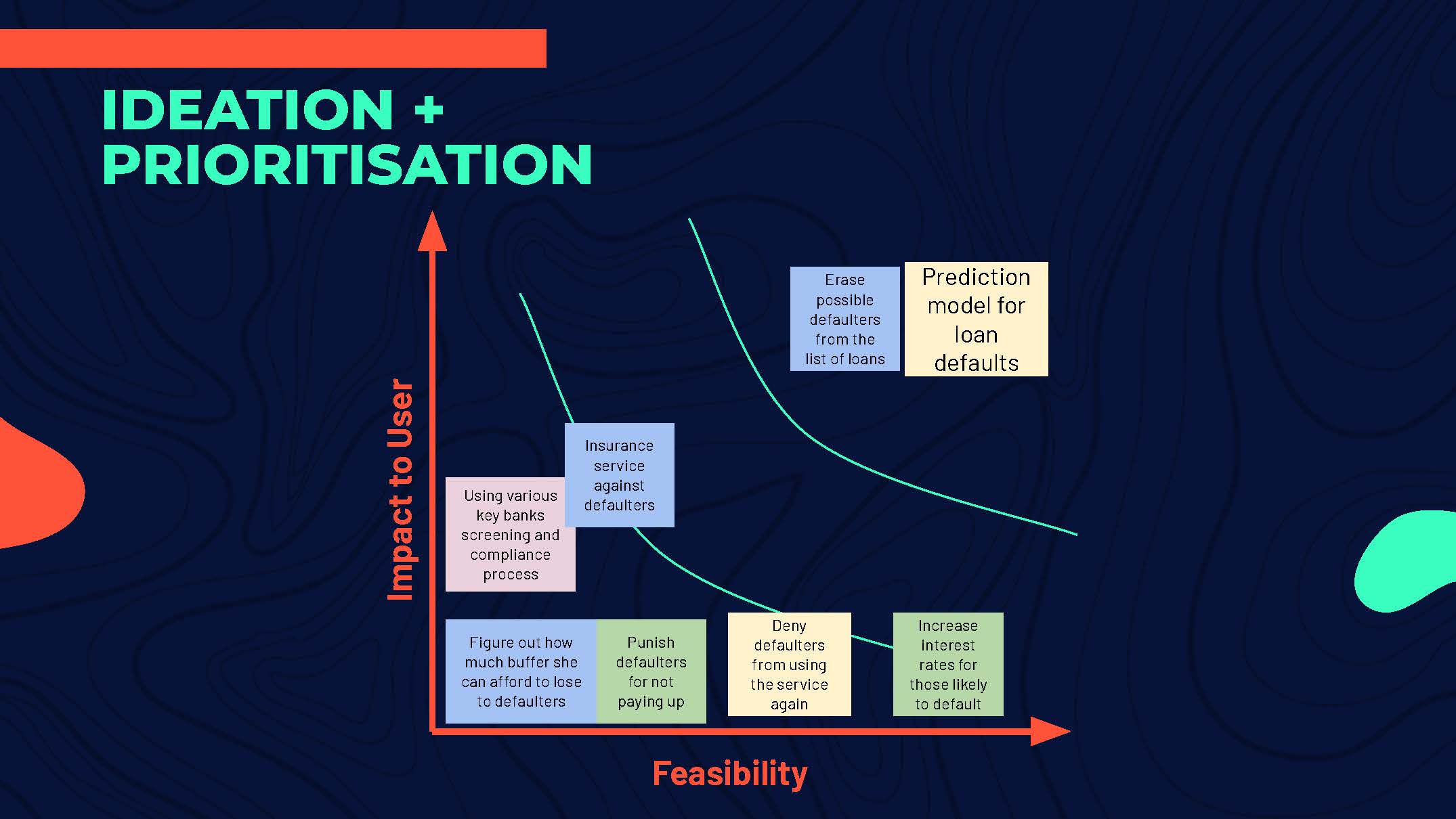
But how does this play out for Beatrice? We plotted a storyboard, allowing us to experience our solution from her point of view.

Tackling the Data
For this project, we had to find a suitable dataset to put through the data science process. In this case, the Lending Club dataset from Kaggle. We felt that it was appropriate as Lending Club is one of the pioneers on P2P lending and is now the world’s largest platform. Its data is also accessible through API calls that allow us to develop our unique solution for ABZ Capital.
In our data exploration phase, we found several interesting insights. Firstly, longer-term loans tend to have higher default rates. This made sense as people with lower creditworthiness is less likely to be able to afford the high instalment rates on short term loans. Next, loans with lower creditworthiness grades are more likely to default. Now, this might imply that there is already an existing measure for mitigating defaulters, which questions the value of our project. However, there are still default risks even in the highest grades. By having our solution and the grading system, Beatrice will have two filters in her arsenal against potential defaulters.

Next, we moved forward with cleaning up the data. We found several variables in the data that had little bearing on the default risk. For example, there was very little deviation in default rates throughout the different employment lengths. This meant that how long one has been employed was not a useful predictor and we removed the variable. With fewer variables, the size of our data is reduced, speeding up the machine learning process. Aside from this, we applied one-hot encoding to where appropriate and filled up the missing data with mean values.

The data was split, 80% for training and 20% for testing. As we were looking at a binary outcome, we used three classification models: Logistic Regression, Random Forest Classifier and XGBoost. Although XGBoost gave us the highest testing accuracy, we decided on the model generated by the Random Forest Classifier. We felt that it was more important to focus on the precision of the model as we wanted to avoid false negatives as much as possible.
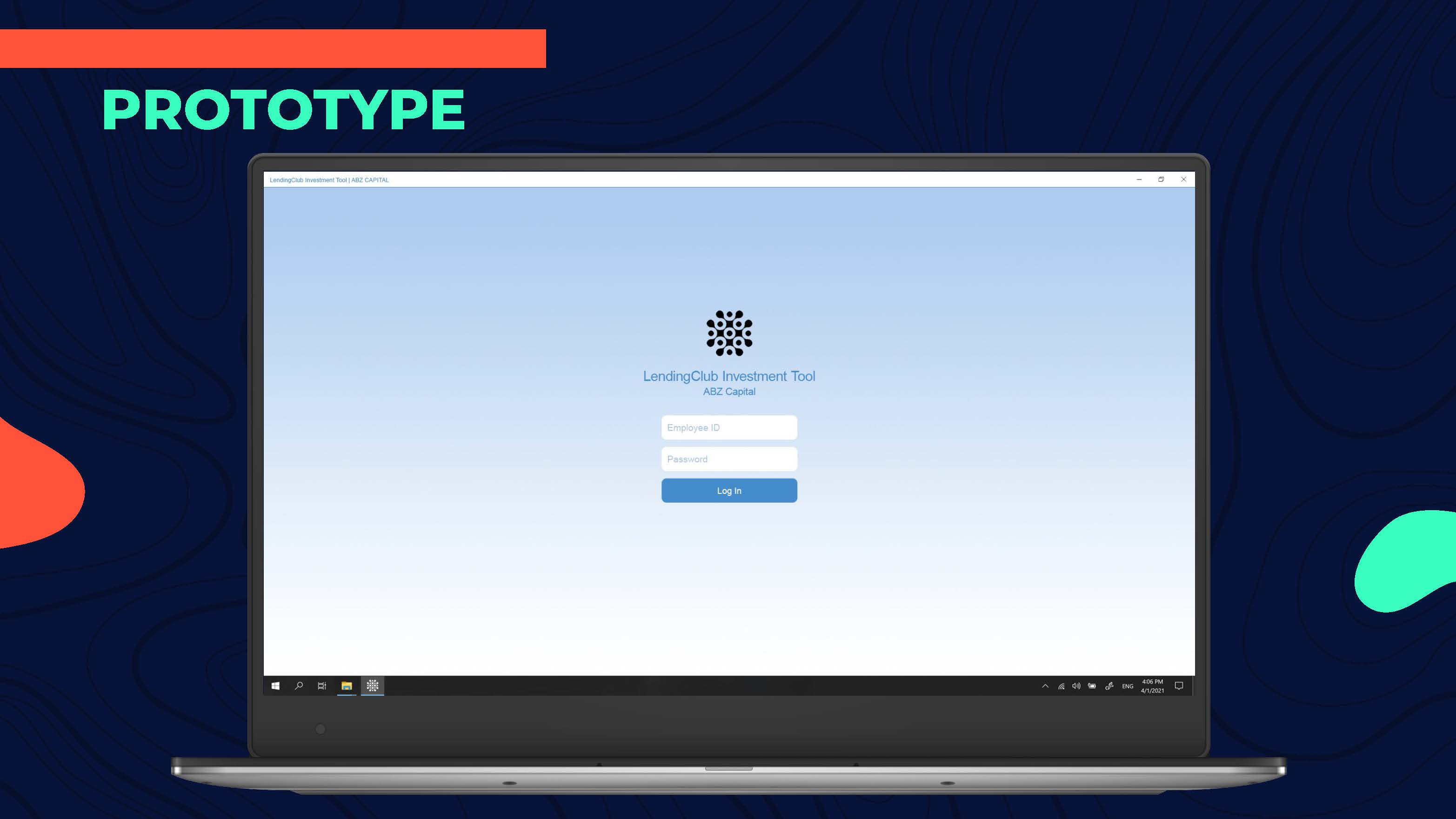
Topping it up with a Mockup
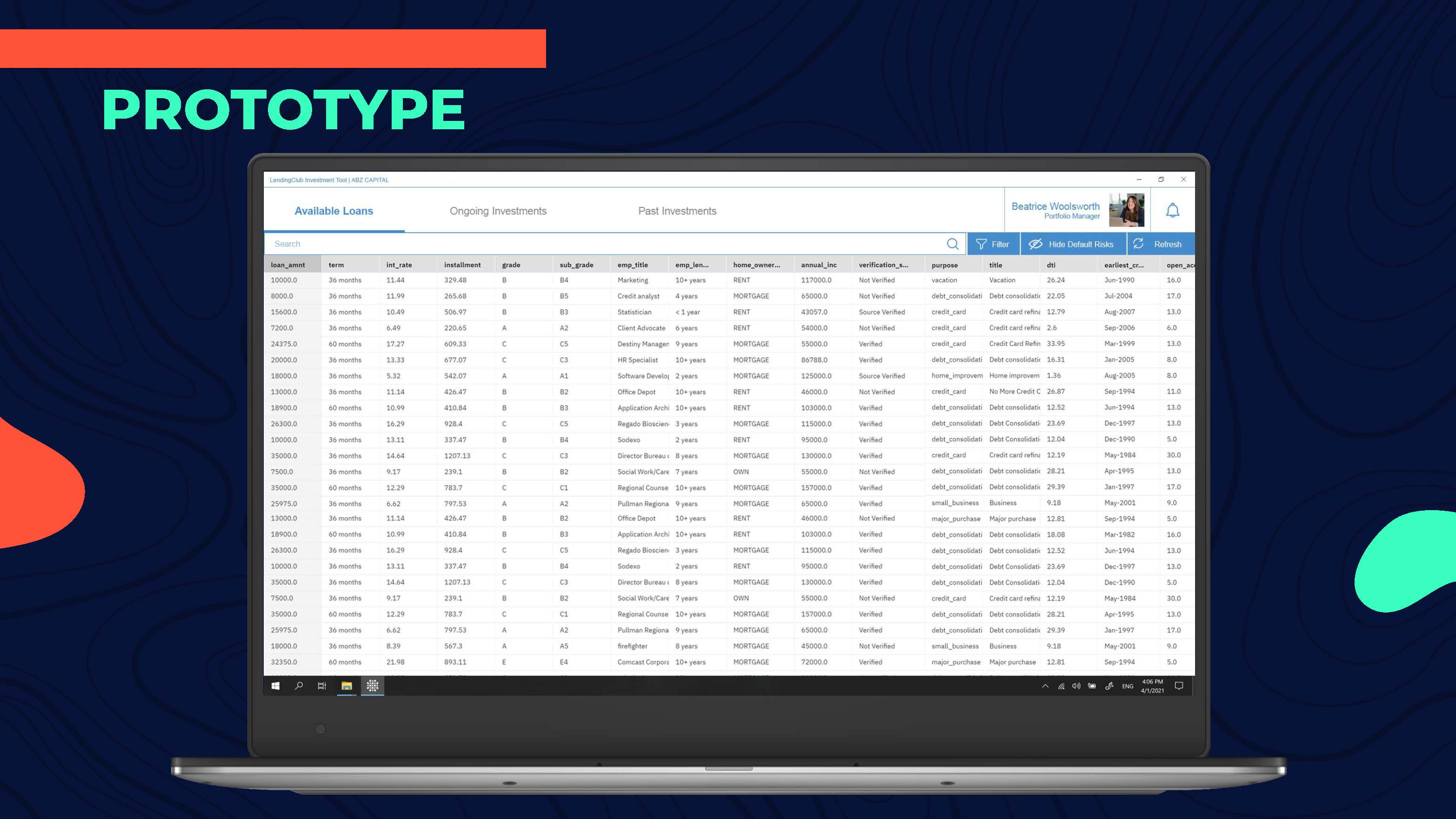
As our final deliverable, we made a quick mockup to visualize how our solution might look like for Beatrice.
| Programme | SGUnited Mid-Career Pathways IBM I.am-vitalize Data Science and AI Programme | Team | Ang Peng Da, Richard Chee, Goh Kah Kiat |